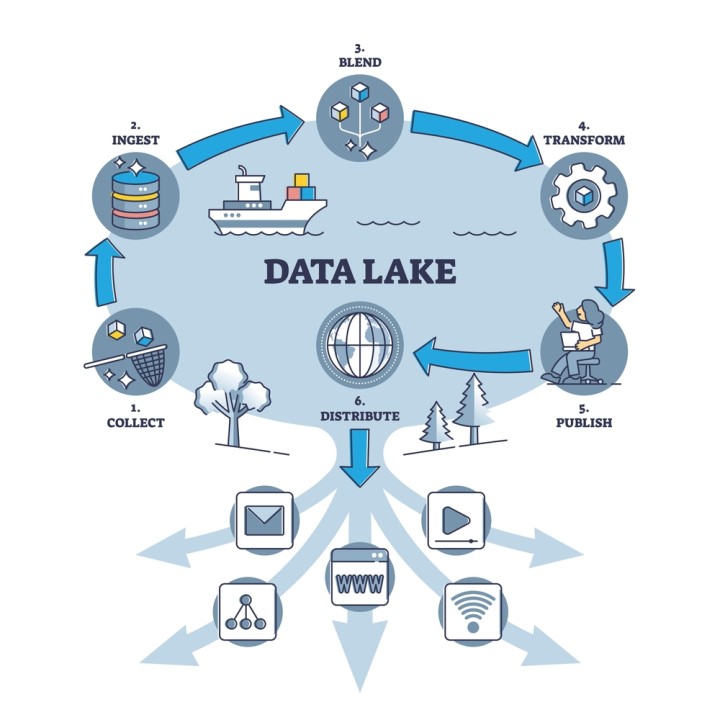
Data Lake, what is it in real?
Where to store your underlying Big Data, to let Analytics been done over?
You might hear about what is called “Data Lake”, but what is it in real? And why is it very important in modern life? Let’s figure it out together.
A data lake is a storage repository that holds a large amount of data in its native, raw format. Data lake stores are optimized for scaling to terabytes and petabytes of data. The data typically comes from multiple heterogeneous sources and may be structured, semi-structured, or unstructured. The idea with a data lake is to store everything in its original, untransformed state. This approach differs from a traditional data warehouse, which transforms and processes the data at the time of ingestion.

The following are key data lake use cases (as shown in the image):
- Cloud and IoT data movement
- Big data processing
- Analytics
- Reporting
- On-premises data movement
Here we would like to focus on the use case of Analytics, as we mentioned earlier. Thus, we want to keep you focused on why Power BI and Azure Analytics users should take data lakes into consideration.
Let us take Microsoft as a great example to illustrate some facts.
Microsoft, Power BI, and Azure data services have teamed up to leverage Common Data Model (CDM) folders as the standard to store and describe data, with Azure Data Lake Storage as the shared storage layer. So, CDM is the shape of how data is stored in Azure Data Lake.
About Azure Data Lake
Azure Data Lake Storage (generation 2) is Microsoft’s solution for big data storage – it’s where organizations accumulate and amass any data that may have intelligence/analytical value. At the highest level, Azure Data Lake is an organized storage container (with both object and hierarchical access models). It enables best-in-class analytics performance along with Blob storage’s tiering and data lifecycle management capabilities, plus the fundamental availability, security (including AAD integration and ACL support), and durability capabilities of Azure Storage.
About CDM
Microsoft has created the Common Data Model (CDM) in partnership with an industry ecosystem that defines a mechanism for storing data in an Azure Data Lake that permits application-level interoperability.
More specifically, the goal is to permit multiple data producers and data consumers to easily interoperate over raw storage of an Azure Data Lake Storage (ADLSg2) account (without necessarily requiring additional cloud services for indexing/cataloging contents) to accelerate value from data by minimizing time and complexity to insight and intelligence.
The CDM accomplishes this by bringing structural consistency and semantic meaning to the data stored in a CDM-compliant Azure Data Lake. The primary reason that CDM and CDM Standard Entities exist on the intelligence/analytics side is to bring semantic meaning to data (and structural consistency, but that is secondary and in support of the out-of-box semantic model). Note that this provides an expanded definition of CDM to cover structural aspects of the data lake, in addition to individual entity definitions.
Azure data lake provides Power BI dataflows with an enormously scalable storage facility for data. ADLSg2 can be thought of as an enormous disk with incredible scale and inexpensive storage costs. ADLSg2 also supports the HDFS (Hadoop File System) standard, which enables the rich Hadoop ecosystem including Hive, Spark, and MapReduce, to operate on it.
Benefits of Azure Data Lake
By moving the data to the tenant’s storage account (“BYOSA – Bring Your Own Storage Account”), the IT organization can access that data by using a host of Azure data services, which allows data engineers and scientists a rich toolset with which to process and enrich the data.

Open approach with Power BI
The ability to create a collection of data services and applications that are processing and exchanging data through ADLSg2 is a key feature of Power BI. It creates a strong and direct link between the business-driven data assets created by business analysts through the dataflows with the strong technical capabilities of the IT pros who use advanced data services to provide depth and solve difficult challenges.
It also allows Power BI to easily work with large volumes of observational data that is directly deposited to the data lake by various IoT, logs, and telemetry applications. Since Power BI sits directly above ADLSg2, this observational data can be mounted directly and used in dataflows without requiring any data movement.
To allow easy data exchange, Power BI stores the data in ADLSg2 in a standard format (CSV files) and with a rich metadata file describing the data structures and semantics in special folders (the CDM folders).